


Macom (MTSI US) – A Hidden Nvidia GB200 Play (updated version)

I first wrote an article on Macom in early April, after the OFC conference, discussing the new GB200 content dollar opportunity for this US listed company. Thereafter, I attended the Taiwan Computex exhibition in June and visited the booths of Amphenol and several major GB200 ODMs. This article is an updated version of the Macom article, based on the new information gathered from my field research in June.
In order to understand Macom's specific content dollar opportunity in GB200, we first need to have a basic understanding of the interconnection methods of GB200. Jenson showed the following picture of the GB200 NVL576 Super Pod (i.e., the interconnection of 576 GPUs) at his presentation in early June:

Based on my field research at the Computex, a standard NVL576 Super Pod should consist of 8 NVL72 GB200 racks and 4 switch racks. The picture above only shows four GB200 racks (the yellow/green line cabinets), and there should be four more GB200 racks in the back row. On the right side of the front row of four GB200 racks, there are four switch racks (blue line cabinets) placed side by side, containing IB switches for east-west traffic connections. Each GB200 rack has 9 NVL switch trays inside, connected to 18 compute trays through backend network which uses cable cartridge for the interconnection of 72 GPUs within the rack (note that the NVL switch trays themselves do not have a frontend panel, so the GPU interconnection between racks must go through the frontend network of the compute trays). Additionally, each GB200 rack also has a Top-of-Rack switch for north-south traffic connections. Some readers might also notice a blue line cabinet on the left side of the GB200 racks in the chart above, but this switch rack does not involve in the GPU interconnection of the NVL576 Super Pod and is used to support other miscellaneous networks (e.g., debug network, in-band management network, etc.).
After explaining the network layout from top-down level, let's also take a look at the network layout of a single GB200 compute tray from bottom-up level (see the chart below):
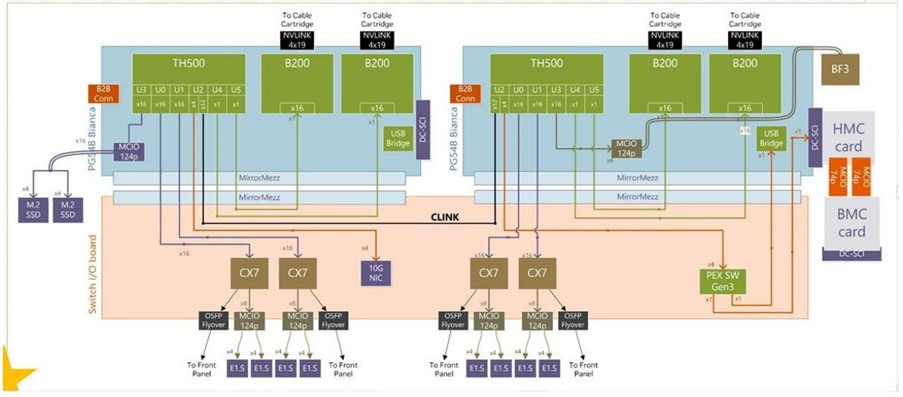
The above is a simple diagram of a standard GB200 Bianca compute tray. We can see that each compute tray is equipped with four backend network ports which are connected to the 9 NVL switch trays in the middle of the GB200 rack through the cable cartridge. The frontend network is connected to the first layer of the switch network through four NICs (currently shown as CX7 in the diagram, but the actual GB200 that will be mass-produced next year will be upgraded to CX8) with four OSFP ports. According to the mass production specifications for next year, I assume that the standard frontend network adopts four CX8 NICs with four 800G OSFP ports for east-west traffic connections. NVDA requires that IB switches must be adopted for east-west traffic connections, with a 1:1 convergence ratio for networking. Here I use a maximum three-layer network as an example to illustrate the east-west traffic network architecture of the NVL576 Super Pod: the first layer network consists of four frontend 800G OSFP ports of each GB200 compute tray, connected to the IB switches in the adjacent switch racks via optical fiber. One end of each optical fiber (compute tray side) connects with two 800G LPO modules, and the other end (IB switch side) connects with a 1.6T DSP module bifurcating into two 800G ports of the Quantum X800 IB switch. The Quantum X800 IB switch has a total of 144 800G ports. Simple calculations show that to form a 576 GPU interconnection with a 1:1 convergence ratio, a total of 576/(144/2)=8 first-layer switches, 8 second-layer switches, and 576/144=4 third-layer switches are required. Each first and second-layer switch has 72 ports for the downstream network and 72 ports for the upstream network, while the third-layer switch has all 144 ports for the downstream network. Each switch layer is interconnected by 1.6T optical modules. In practice, due to the high cost of 1.6T optical modules, CSP customers will deploy different levels of switches into the same switch racks whenever possible. This allows in-rack switch connections to use cheaper 1.6T ACC solution instead of optical modules.
For the north-south traffic connection, NVDA recommends Ethernet switch as ToR switch being connected with 800G ACC. One end of each ACC is bifucrated and connected to the two 400G OSFP ports of the compute tray (with two BF3 DPUs inside), and the other end is connected to an 800G port of the ToR switch. NVDA's Spectrum-X800 Ethernet switch has a total of 64 800G ports, of which 36 ports are responsible for the downstream network, connecting 36 compute trays, and the remaining 28 ports are reserved for the upstream network, which is formed according to certain bandwidth convergence ratio based on the needs of CSP customers. Ethernet switches are interconnected using 800G DSP optical modules.
There is also a question on why NVDA chose non-DSP solutions like ACC or LPO for interconnections in GB200 racks vs. AEC or traditional DSP optical modules (I explained the difference between AEC and ACC in the previous article on Credo: Credo (CRDO US) – A Hidden ASIC Server Play). The answer is simple: Compared to traditional DSP, pure analog devices like ACC and LPO have advantages of low latency, low power consumption, and better heat dissipation. This is particularly important for AI server clusters where signal transmission delay and heat dissipation are major issues. Traditional DSP modules cause about 200 nanoseconds of signal transmission delay, while analog devices can control the delay within 5 nanoseconds, which is significantly beneficial for large-scale data training and inference in AI servers. Similarly, removing the DSP reduces the power consumption of LPO modules by almost half as compared with DSP modules, greatly reducing heat dissipation requirements. Therefore, NVDA prefers ACC and LPO solutions in GB200, which were previously considered non-mainstream solutions by the industry.
After understanding the interconnection method of GB200, we can now estimate Macom's specific content dollar opportunity. According to my understanding, Macom provides four different products in NVDA GB200: linear equalizers in 1.6T & 800G ACC, TIA+driver in 800G LPO modules, and driver in 1.6T DSP optical modules. These product details will be explained below.